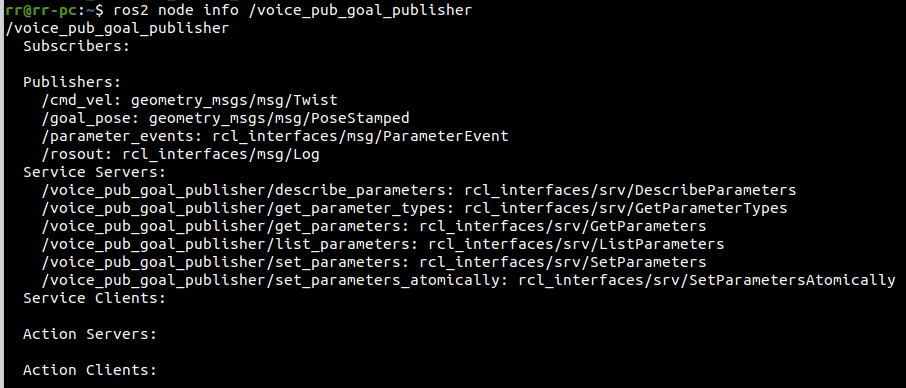
6. Voice control multi-point navigation
6. Voice control multi-point navigation6.1, Functional description6.2. Preparation6.2.1 Bind the voice control device ports in the host computer.6.2.2 Mounting the voice control device in the docker container6.3. Configure the navigation point6.4. Using voice multi-point navigation6.5 Node resolution6.5.1. Displaying a computational graph6.5.2. Voice control node details
The operating environment and hardware and software reference configuration are as follows:
- Reference model: ROSMASTER X3
- Robot hardware configuration: Arm series main control, Silan A1 LiDAR, AstraPro Plus depth camera.
- Robot system: Ubuntu (version not required) + docker (version 20.10.21 and above)
- PC virtual machine: Ubuntu (20.04) + ROS2 (Foxy)
- Usage scenario: use on a relatively clean 2D plane
6.1, Functional description
By interacting with the voice recognition module on the ROSMASTER, voice control can be realized to realize multi-point navigation in the built map;
Note: Before using the functions in this subsection, please learn to use the module [----- map building navigation function in LiDAR series course];
6.2. Preparation
This lesson requires the use of a voice control device, and the following preparations need to be made before running this lesson:
6.2.1 Bind the voice control device ports in the host computer.
Please refer to this section [1. Introduction to the module and the use of port binding].
6.2.2 Mounting the voice control device in the docker container
When you enter the docker container, you need to modify the script that enters the container to mount the voice control device:
Add this line to the [run_docker.sh] script:
xxxxxxxxxx--device=/dev/myspeech \ # 添加这行# Add this line
Other modifications as you see fit:
xxxxxxxxxx#!/bin/bashxhost +docker run -it \--net=host \--env="DISPLAY" \--env="QT_X11_NO_MITSHM=1" \-v /tmp/.X11-unix:/tmp/.X11-unix \-v /home/jetson/temp:/root/yahboomcar_ros2_ws/temp \-v /home/jetson/rosboard:/root/rosboard \-v /home/jetson/maps:/root/maps \-v /dev/bus/usb/001/010:/dev/bus/usb/001/010 \-v /dev/bus/usb/001/011:/dev/bus/usb/001/011 \--device=/dev/astradepth \--device=/dev/astrauvc \--device=/dev/video0 \--device=/dev/myserial \--device=/dev/rplidar \--device=/dev/myspeech \ # 添加这行# Add this line--device=/dev/input \-p 9090:9090 \-p 8888:8888 \yahboomtechnology/ros-foxy:3.5.4 /bin/bash
6.3. Configure the navigation point
1, enter the container, see [docker course in ----- 5, enter the docker container of the robot], sub-terminal execution of the following command:
xxxxxxxxxxros2 launch yahboomcar_nav laser_bringup_launch.py
- Open the virtual machine, configure multi-machine communication, and then execute the following command to display the rviz node
xxxxxxxxxxros2 launch yahboomcar_nav display_nav_launch.py
- execution of navigation nodes in docker containers
xxxxxxxxxxros2 launch yahboomcar_nav navigation_teb_launch.py
4, this time in the virtual machine rviz interface click [2D Pose Estimate], and then compared to the position of the car in the map to the car mark an initial position;
After marking the display is as follows:
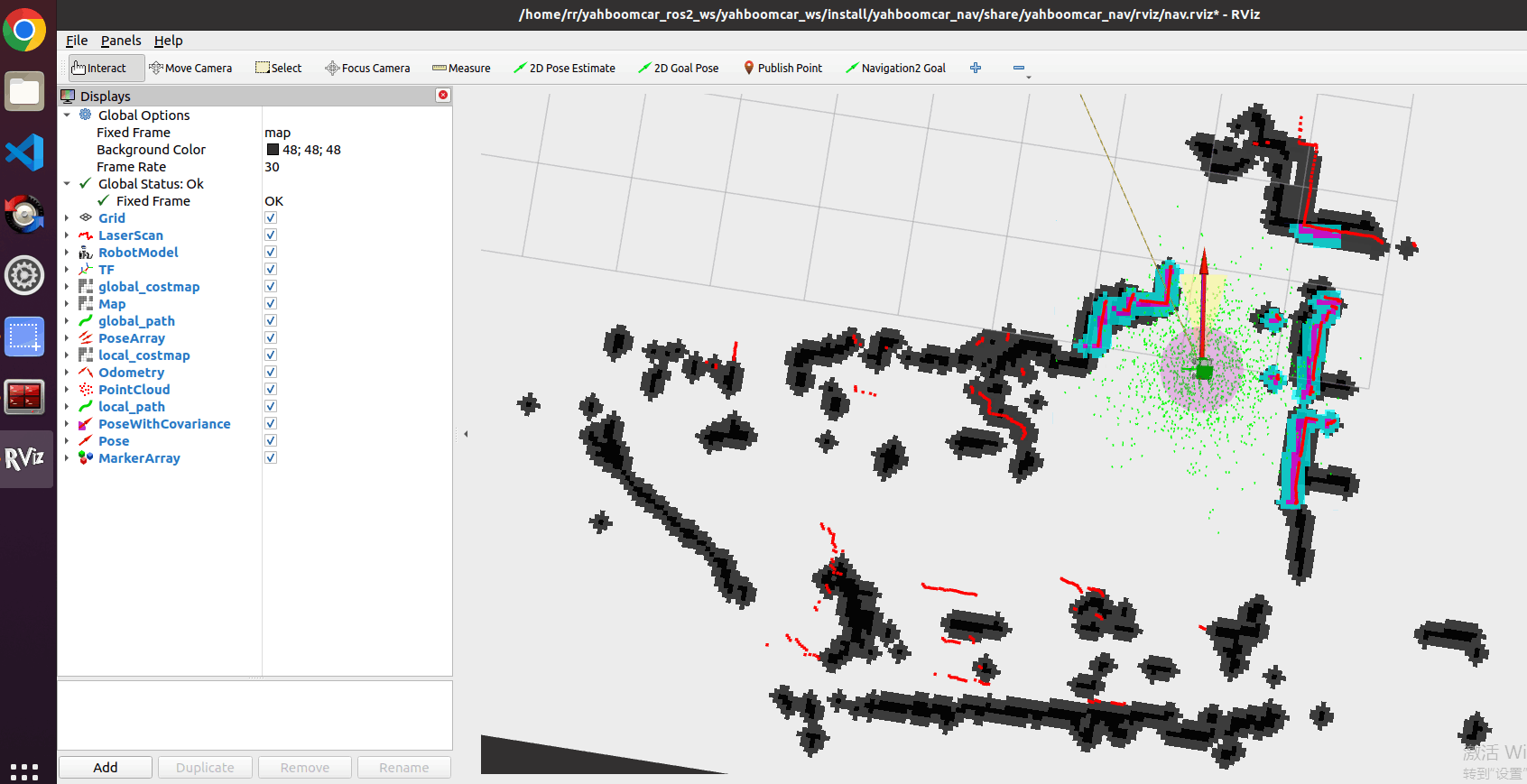
- Compare the overlap between the radar scanning point and the obstacle, you can set the initial position for the cart several times until the radar scanning point and the obstacle roughly overlap;
6, open another terminal into the docker container, execute the
xxxxxxxxxxros2 topic echo /goal_pose # 监听 /goal_pose话题# Listening to /goal_pose topics
7, click [2D Goal Pose], set the first navigation target point, this time the cart began to navigate, while 6 steps in the topic data will be received listening:
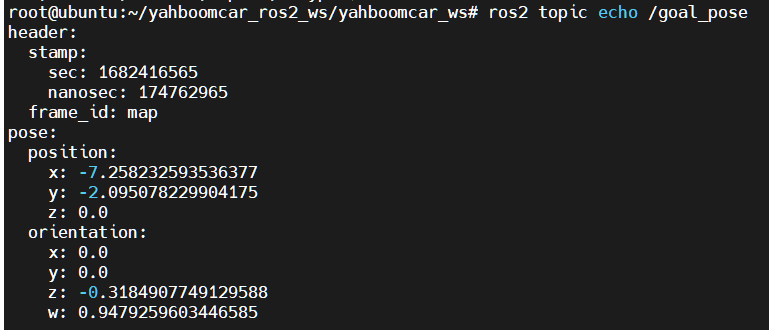
- Open the code in the following location:
xxxxxxxxxx/root/yahboomcar_ros2_ws/yahboomcar_ws/src/yahboomcar_voice_ctrl/yahboomcar_voice_ctrl/voice_Ctrl_send_mark.py
Modify the positional attitude of the first navigation point to that printed in step 7:
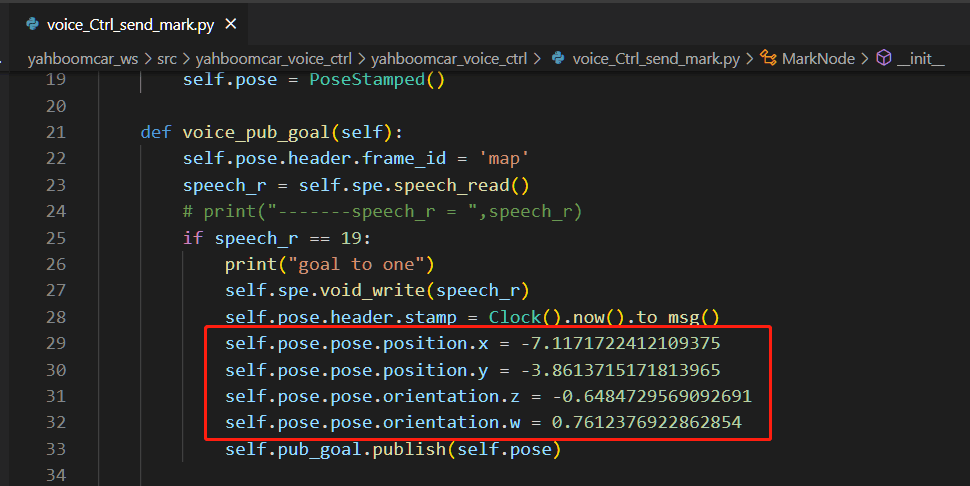
- Modify the position of the other 4 navigation points in the same way.
6.4. Using voice multi-point navigation
- Enter the container, see [5. Enter the docker container of the robot], and execute the following command in a sub-terminal:
xxxxxxxxxxros2 launch yahboomcar_nav laser_bringup_launch.py
- Open the virtual machine, configure multi-machine communication, and then execute the following command to display the rviz node
xxxxxxxxxxros2 launch yahboomcar_nav display_nav_launch.py
- execution of navigation nodes in docker containers
xxxxxxxxxxros2 launch yahboomcar_nav navigation_teb_launch.py
4, this time in the virtual machine rviz interface click [2D Pose Estimate], and then compared to the position of the car in the map to the car mark an initial position;
After marking the display is as follows:

- Compare the overlap between the radar scanning point and the obstacle, you can set the initial position for the cart several times until the radar scanning point and the obstacle roughly overlap;
6, open another terminal into the docker container, the execution of the opening of the voice control navigation node
xxxxxxxxxxros2 run yahboomcar_voice_ctrl voice_Ctrl_send_mark
7, to the voice module on the car said "Hello, Xiaoya" wake up the voice module, hear the voice module feedback broadcast "in the", continue to say "navigation to the first position"; voice module will feedback broadcast "good, is going to the first position", at the same time the car began to navigate to the first position. After hearing the feedback from the voice module "yes", continue to say "navigate to position 1"; the voice module will announce "OK, going to position 1", and at the same time, the cart will start to navigate to position 1. Other position navigation can be used in the same way. Refer to the following table for voice control function words:
| function word | Speech Recognition Module Result | Contents of the voice announcement |
|---|---|---|
| Navigate to position one. | 19 | Okay. Going to one. |
| Navigate to position two. | 20 | Okay. Going to two. |
| Navigate to position three. | 21 | Okay. Going to three. |
| Navigate to position four. | 32 | Okay. Going to four. |
| return to square one | 33 | Okay, it's coming back around. |
6.5 Node resolution
6.5.1. Displaying a computational graph
xxxxxxxxxxrqt_graph
6.5.2. Voice control node details